前言
Tensorflow官方推出了可视化工具Tensorboard,它可以将模型训练过程中的各种数据汇总起来存在自定义的路径与日志文件中,然后在指定的web端可视化地展现这些信息。
当使用Tensorflow训练大量深层的神经网络时,我们希望去跟踪神经网络的整个训练过程中的信息,比如迭代的过程中每一层参数是如何变化与分布的,比如每次循环参数更新后模型在测试集与训练集上的准确率是如何的,比如损失值的变化情况,等等。这些都可以用Tensorboard可视化出来。
tensorflow的可视化是使用summary和tensorboard合作完成的.不过我们首先需要在神经网络代码中设置可视化参数。
TensorBoard:可视化学习——官方文档
设置可视化参数
想将整个神经网络的框架可视化出来,就必须先设置框架中每个元素的可视化参数。
设置节点和名称
设置节点可视化参数使用上下文管理器with语法,用tf.name_scope()实现。
-
定义Python操作时使用上下文管理器with。
例如,针对单个变量:
1 | with tf.name_scope('weights'): |
例如,给对象加个name:
1 | with tf.name_scope('inputs'): |
例如,针对某层:
1 | def my_op(a, b, c, name=None): |
设置变量直方图
直方图需要在之后的tensorboard中的hietograms标签下观看。
在这之前我们需要对每个检测对象进行设置:
针对变量
也许你也想看到一个特定层的激活分布,或梯度或权重的分布。通过将tf.summary.histogramops分别附加到梯度输出和保存权重的变量来收集这些数据 。
-
1
2
3
4
5
6histogram(
name,
values,
collections=None,
family=None
)Summary用直方图输出协议缓冲区。添加直方图汇总可以使数据在TensorBoard中的分布可视化。您可以在这里看到TensorBoard直方图仪表板的详细说明 。
生成的
Summary具有一个包含直方图的汇总值values。InvalidArgument如果任何值不是有限的,则这个op报告一个错误。
针对标量
假设您正在训练用于识别MNIST数字的卷积神经网络。您想记录学习率随时间的变化,以及目标函数如何变化。通过将tf.summary.scalar操作附加到分别输出学习率和丢失的节点来收集这些数据。
-
1
2
3
4
5
6scalar(
name,
tensor,
collections=None,
family=None
)输出
Summary包含单个标量值的协议缓冲区。生成的摘要包含一个包含输入张量的Tensor.proto。
合并摘要并保存至文件
合并摘要设置
在运行之前,TensorFlow中的操作不会执行任何操作,或者取决于其输出的操作。我们刚刚创建的摘要节点是图形的外围设备:您当前正在运行的所有操作都不依赖于它们。所以,为了生成摘要,我们需要运行所有这些汇总节点。 tf.summary.merge_all 可以将它们合并成一个单一的操作,生成所有的汇总数据。
-
1
merge_all(key=tf.GraphKeys.SUMMARIES)
合并在默认图表中收集的所有摘要。
ARGS:
- key:
GraphKey用来收集摘要。默认为GraphKeys.SUMMARIES。
例:
1
2sess = tf.Session()
merged = tf.summary.merge_all() - key:
上面的merge只是设置,在最后的循环训练中通过run才能发挥作用,然后再将其写入文件。
例:
1 | for i in range(1000): |
向文件添加数据
使用tf.summary.FileWriter()将整个可视化设置加载到一个文件中,之后我才能将文件加载到浏览器中可视化。
-
将缓冲区
Summary协议数据写入硬盘文件。本
FileWriter类提供了一个机制来创建指定目录的事件文件,并添加摘要和事件给它。该类异步更新文件内容。这允许训练程序调用直接从训练循环向文件添加数据的方法,而不减慢训练。
例子:
1 | sess = tf.Session() |
‘your_dir’——文件存放路径
注:必须先定义了Session(初始化)之后才能tf.summary.FileWriter()
summary函数介绍
tf.summary.merge_all: 将之前定义的所有summary op整合到一起FileWriter: 创建一个file writer用来向硬盘写summary数据,tf.summary.scalar(summary_tags, Tensor/variable): 用于标量的summarytf.summary.image(tag, tensor, max_images=3, collections=None, name=None):tensor,必须4维,形状[batch_size, height, width, channels],max_images(最多只能生成3张图片的summary),觉着这个用在卷积中的kernel可视化很好用.max_images确定了生成的图片是[-max_images: ,height, width, channels],还有一点就是,TensorBord中看到的image summary永远是最后一个global step的tf.summary.histogram(tag, values, collections=None, name=None):values,任意形状的tensor,生成直方图summarytf.summary.audio(tag, tensor, sample_rate, max_outputs=3, collections=None, name=None)
启动TensorBoard
上面的步骤成功之后,events file就躺在你磁盘上logdir位置上了。
要运行TensorBoard,请在命令行键入以下命令
(或者python -m tensorboard.main)
1 | tensorboard --logdir=path/to/log-directory |
其中logdir指向FileWriter序列化其数据的目录。如果这个logdir目录包含包含来自单独运行的序列化数据的子目录,那么TensorBoard将可视化来自所有这些运行的数据。

然后浏览器输入给出的地址(红框中链接)
这样你就可以在tensorboard中看到你的网络结构图了。
在看TensorBoard时,您会看到右上角的导航标签。每个选项卡代表一组可以可视化的序列化数据。

有关如何使用图形选项卡可视化图形的深入信息,请参阅TensorBoard:图形可视化。
有关如何使用TensorBoard直方图仪表盘——官方文档
有关TensorBoard的更多使用信息,请参阅TensorBoard的GitHub。
图形可视化
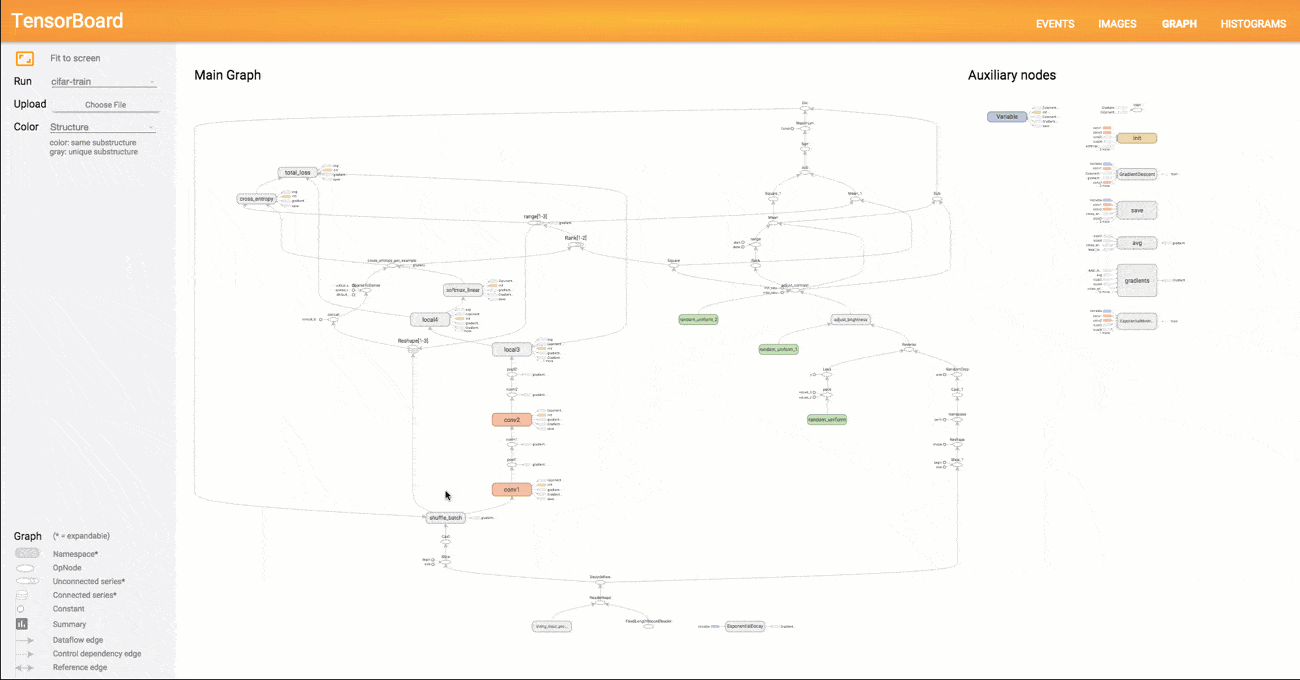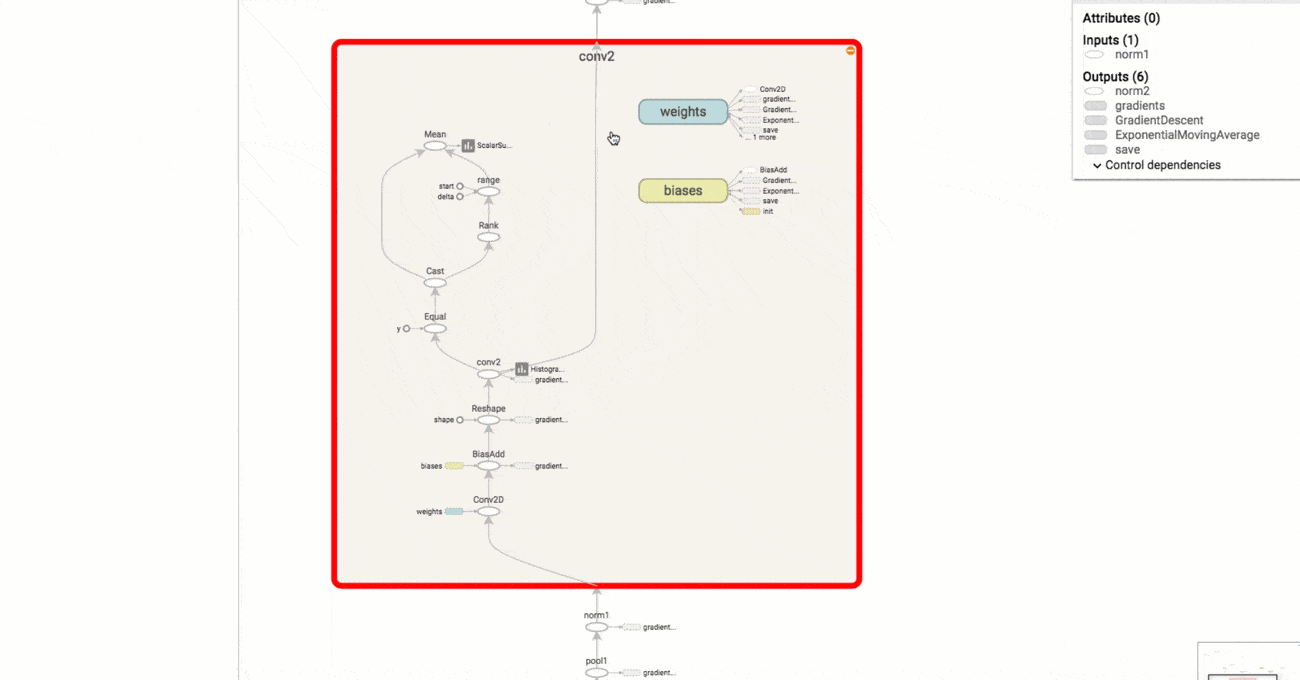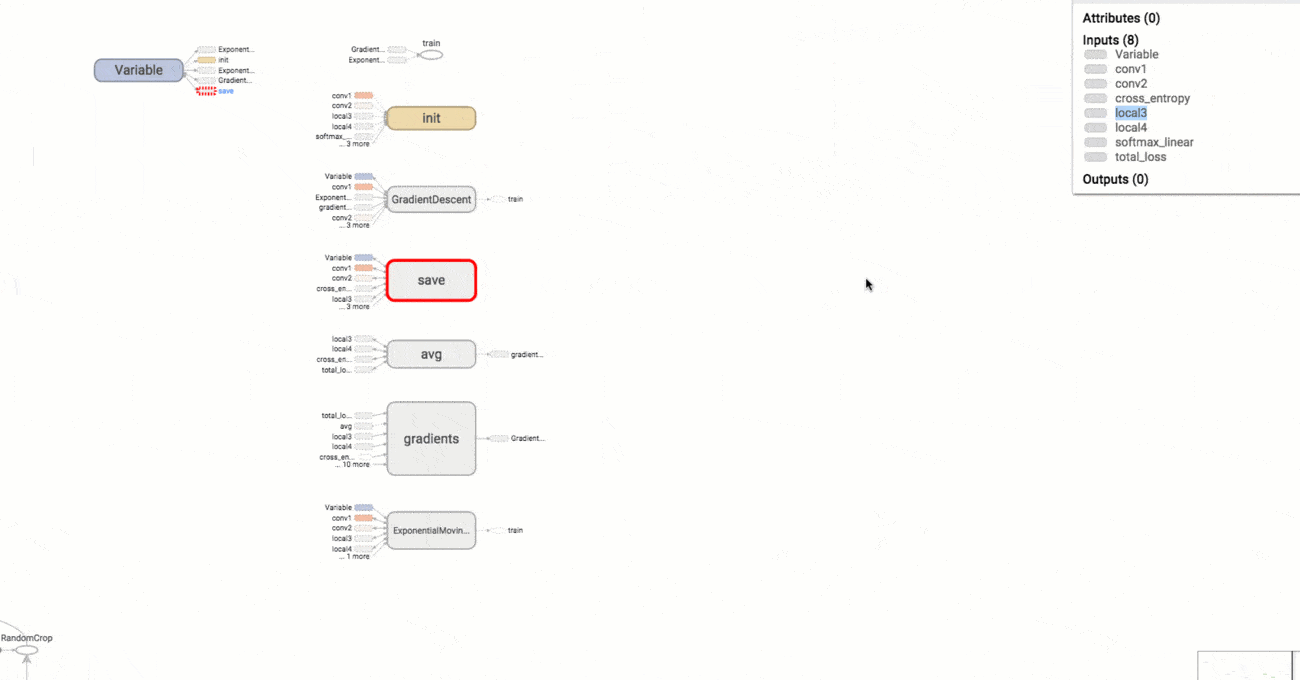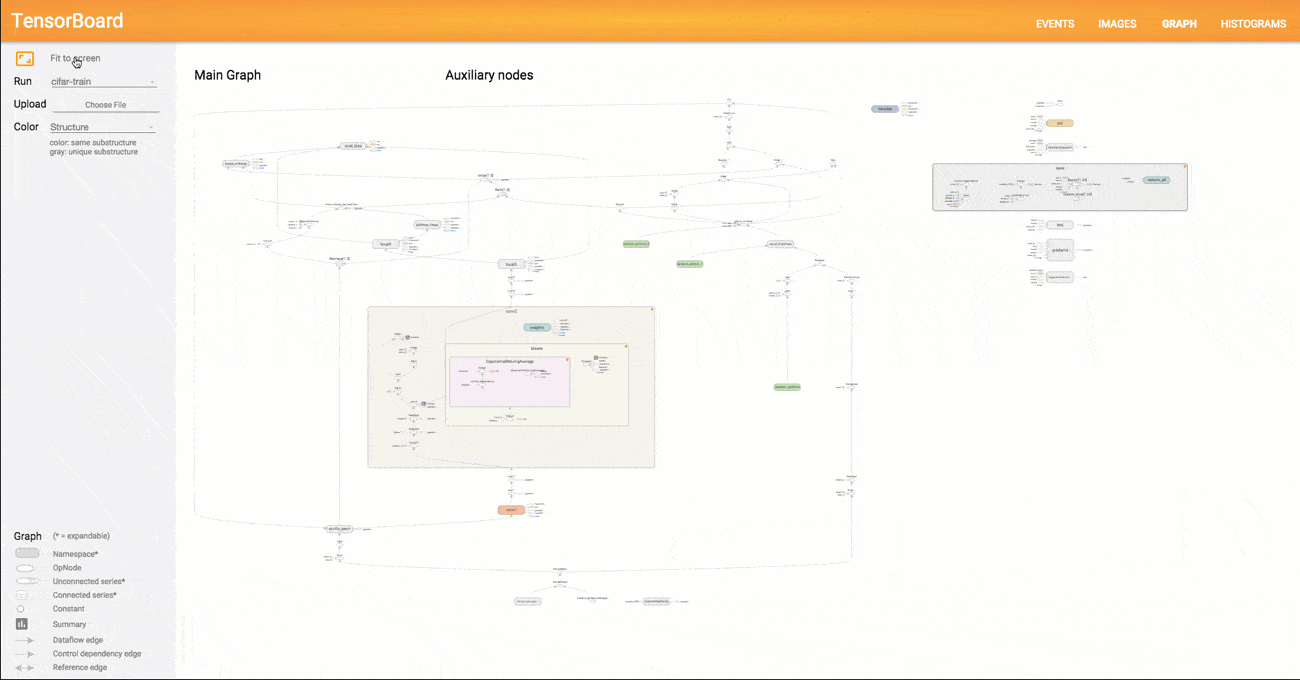
典型的TensorFlow图可以有成千上万个节点 - 太多的节点很难一次看到,甚至无法使用标准的图形工具进行布局。为简化起见,变量名可以作用域,可视化使用这些信息来定义图中节点上的层次结构。默认情况下,只显示该层次结构的顶部。这里是一个例子,在hidden名称范围下使用 tf.name_scope以下命令定义三个操作 :
1 | import tensorflow as tf |
按名称范围对节点进行分组对于制作清晰的图形至关重要。如果你正在构建模型,则名称范围可以控制生成的可视化。 你的名字范围越好,你的可视化就越好。
下面是一个节点符号表:
| 符号 | 含义 |
|---|---|
 |
*表示名称范围的高级*节点。双击以展开高级节点。 |
 |
编号节点序列没有相互连接。 |
 |
相互连接的编号节点序列。 |
 |
一个单独的操作节点。 |
 |
一个常数。 |
 |
摘要节点。 |
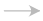 |
边缘显示操作之间的数据流。 |
 |
边缘显示操作之间的控制依赖关系。 |
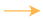 |
显示传出操作节点可以改变传入张量的参考边缘。 |
